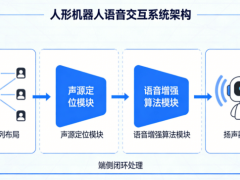
在即将到来的gtc 2026大会上,英伟达创始人黄仁勋的布局引发行业震动。这次他不再单纯展示参数飙升的gpu,而是亮出一张200亿美元的“技术底牌”——基于sram的专用推理芯片。这一动作背后,是英伟达对ai算力市场格局的深度重构,更是一场精心设计的商业防御战。
半导体物理定律早已为存储技术划下清晰界限。sram单元需6个晶体管存储1比特数据,而dram仅需1个晶体管加1个电容。这种结构差异导致sram的硅片面积是dram的5-10倍,虽然具备纳秒级访问速度,但容量成本高昂,难以承载千亿参数大模型。英伟达的破局之道在于重新定义算力分工:用hbm支撑云厂商的大模型训练,用sram打造专用推理芯片,形成“训练-推理”的算力阶级体系。
行业趋势的转变成为关键推手。思科等机构预测,到2027年75%的ai工作负载将转向实时推理场景。当meta等巨头开始将推理业务向谷歌tpu迁移,当groq等初创公司以专用芯片威胁英伟达市场地位,黄仁勋不得不打破自己坚持多年的“通用gpu万能论”。新推出的lpu(语言处理单元)通过片上sram消除数据搬运延迟,专攻金融交易、自动驾驶等对延迟敏感的领域,形成与训练芯片的差异化竞争。
这场转型暗藏精妙的资本运作。为规避反垄断审查,英伟达采用“资产收购 技术授权 核心团队挖角”的复合模式:支付200亿美元获取groq核心专利使用权,将创始人jonathan ross及200余名工程师纳入麾下,却保留groq的空壳公司。这种操作既绕开了美国ftc和欧盟的监管红线,又悄然接管了groq生态中超200万开发者资源,完成对潜在竞争对手的“合法掏空”。
产业格局的洗牌已现端倪。hbm虽仍是训练领域的“皇冠明珠”,但“ai必配hbm”的炒作泡沫正在破裂。更致命的是,当英伟达将专用推理芯片无缝接入cuda生态,初创公司仅凭底层架构创新突围的路径被彻底封死。过去靠ppt融资的“推理芯片独角兽”们,如今面临裁判亲自下场参战的残酷现实。
黄仁勋的棋局远不止于技术迭代。通过构建“gpu训练 sram推理”的闭环生态,英伟达正将ai数据中心的每一分投入转化为自身利润。当行业还在争论sram与hbm的技术优劣时,这位商业操盘手已悄然完成对ai算力价值链的全面掌控。这场没有硝烟的战争,本质上是科技巨头在监管压力下,通过技术分化和资本运作维持垄断地位的典型样本。