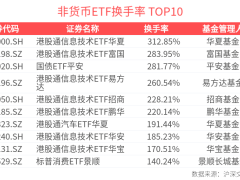
小米近日宣布,其mimo-v2.5系列api完成永久性价格调整,最高降幅达99%,且不限制输入长度。这一举措的背后,是该团队在推理系统全链路优化方面取得的重大突破。此次降价不仅让用户直接受益,更标志着小米在大模型推理技术领域实现了关键性进展。
技术突破与工程落地之间存在显著鸿沟。初期主流开源框架对swa的支持存在缺陷,实质上是以存储完整kvcache的代价兼容swa模式,导致理论收益难以兑现。小米团队通过系统性重构推理栈,从kvcache管理、分级缓存、前缀缓存到调度策略与prefill/decode链路进行全面优化。其中,kvcache双池分治设计将存储拆分为full kv pool与swa kv pool,前者按需增长、长期保存,后者采用环形缓冲区实现窗口级独立淘汰,使存储效率提升约7倍。前缀缓存树重构则通过引入"窗口安全长度"匹配规则、绑定淘汰路径与请求生命周期、支持独立淘汰策略,将线上前缀缓存命中率提升至平均93%,高频用户超过95%。
针对用户对话间隔导致的缓存成本问题,小米自研gcache三级缓存系统实现kvcache在gpu显存、cpu内存和nvme ssd间的自动流转。该系统通过rdma通信实现170gb/s读吞吐和280μs延迟,结合swa的极小存储占用,使相同成本下可承载缓存量成倍提升。在调度优化方面,团队实现kvcache亲和调度与计算量感知优先调度,使l2缓存命中率提升25%,ttft p90降低30%。prefill链路通过缩减expert parallelism至原先1/2、采用三级长度分桶策略,实现端到端性能提升40%。
decode阶段优化聚焦显存利用率提升。通过支持swa的kvcache优化使有效容量提升近5倍,结合cuda graph显存调优与pd分离预分配优化,单节点并发能力显著增强。mimo-v2.5原生支持的3层mtp(multi-token prediction)加速输出技术,使前128 token加速比达2.3倍,128-256 token达1.5倍。在多模态处理方面,团队实现视觉、音频、视频跨模态理解的并行化处理:encoder支持跨请求组batch,图片预处理迁移至gpu,视频解码采用多chunk并行处理,使1小时视频端到端延时从156秒降至23秒,整体encoder吞吐提升至2倍。
这项覆盖hybrid swa moe 多模态组合架构的大规模工程实践,通过系统性优化将理论效率优势转化为真实生产环境收益。小米已将部分优化成果通过pr形式回馈sglang开源社区,并计划持续推进更多开源计划,旨在降低工程优化门槛,推动复合架构的广泛应用。此次api降价正是技术突破的直接体现,用户将以更低成本获得更高性能的模型服务。