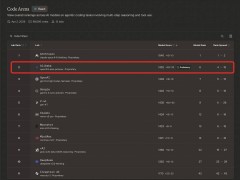
在ai编程能力的全球竞技场上,中国大模型正以强劲势头崭露头角。近日,国际权威盲测平台lmarena旗下code arena榜单公布最新排名,阿里巴巴自主研发的qwen 3.6-plus大语言模型以1452分的成绩跃居全球第二,在react专项技术方向上超越openai、google等国际科技巨头,成为该榜单中排名最高的中国模型。
作为ai领域最具公信力的性能评估平台之一,lmarena通过真实用户盲测与实时对抗机制,为全球大模型提供客观对比。随着ai agent技术兴起,编程能力已成为衡量模型综合实力的核心指标。本次react专项榜单聚焦web开发场景下的自主编码能力,要求模型独立完成从项目初始化到调试运行的全流程,对工程思维与端到端开发能力提出极高要求。qwen 3.6-plus的突破性表现,标志着中国大模型在复杂工程任务处理领域达到世界领先水平。
该模型于4月2日正式发布,具备原生多模态理解与推理能力,尤其在代码生成与agent技术方面表现卓越。在多项权威评测中,qwen 3.6-plus以更少的参数量超越参数量达其2-3倍的glm-5、kimi-k2.5等模型,展现出高效能的技术架构。发布首日即引发全球开发者社区广泛关注,次日便以显著优势登顶react榜单次席,仅落后于anthropic的claude-opus-4.6-thinking(1540分),领先openai最新发布的gpt-5.0-high(1448分)4分,较google的gemini 3.1 pro preview(1440分)高出12分。
在全面评估ai编程能力的code arena总榜单中,qwen 3.6-plus同样稳居中国模型首位。这一成绩推动阿里巴巴在全球ai实验室排名中升至第四,紧随anthropic、openai和google之后。据技术团队透露,qwen 3.6-plus作为千问3.6系列的首发模型,后续将开源不同参数规模的版本,性能更强的旗舰模型qwen3.6-max也计划于近期发布,为开发者提供更丰富的技术选择。